
In today’s data-driven business landscape, the ability to efficiently store, process, and analyze large volumes of data is crucial for staying competitive. As organizations grow and their data needs evolve, many find themselves at a crossroads: continue with their MySQL database or migrate to a more scalable solution like Amazon Redshift. This comprehensive guide will walk you through the process of migrating your data from MySQL to Redshift, ensuring you’re equipped with the knowledge to make this transition smoothly and effectively.
What is MySQL?
MySQL, a popular open-source relational database management system, has long been a go-to solution for businesses of all sizes. Its reliability, ease of use, and robust feature set have made it a staple in the world of data storage and management. However, as data volumes grow exponentially and the need for real-time analytics becomes more pressing, many organizations are looking to cloud-based data warehouse solutions like Amazon Redshift to meet their evolving needs.
What is Redshift?
Amazon Redshift, a fully managed, petabyte-scale data warehouse service in the cloud, offers significant advantages in terms of scalability, performance, and advanced analytics capabilities. By migrating from MySQL to Redshift, businesses can unlock new possibilities in data processing and gain valuable insights that drive strategic decision-making. Amazon redshift is built on top of Postgress.
Advantage of MySQL to Redshift migration
A well-executed migration from MySQL to Redshift can lead to:
- Improved query performance, especially for complex analytical workloads
- Enhanced scalability to handle growing data volumes
- Cost-effective storage and processing of large datasets
- Advanced analytics capabilities, including machine learning integrations
- Seamless integration with other AWS services for a comprehensive data ecosystem
Key differences between MySQL and Redshift
| MySQL | Redshift | |
| Database Type | Traditional RDBMS for OLTP | Cloud-based data warehouse for OLAP |
| Purpose | Frequent small transactions | Large-scale data analytics |
| Scalability | Primarily vertical (scale up) | Easy horizontal (scale out) |
| Query Performance | Fast for small transactions | Optimized for complex analytical queries |
| Data Storage | Row-based storage | Columnar storage |
| Concurrency | High concurrent connections | Fewer users with complex queries |
| Cost Model | Various (on-premises/cloud/open-source) | Pay-as-you-go in AWS ecosystem |
| Data Ingestion | Real-time inserts and updates | Often batch loading for optimal performance |
| Analytics Integration | Widely supported by various tools like Open Source BI Helical Insight | Native AWS integration and broad support using various tools like Open Source BI Helical Insight |
| Maintenance | More hands-on management required | Fully managed service by AWS |
| Data Volume Handling | Suitable for smaller datasets | Designed for petabyte-scale data |
| Use Case | Transactional systems and applications | Business intelligence and big data analytics |
| Performance for Joins | Efficient for complex joins | May require optimization for very large joins |
| Storage Efficiency | Standard compression | High compression ratios with columnar storage |
| Ecosystem | Versatile and widely adopted | Integrated with AWS services |
| Deployment | Flexible (on-premises or cloud) | Cloud-only (AWS) |
| Learning Curve | Widely known and documented | Requires specific Redshift knowledge |
| Data Consistency | ACID compliant | Eventually consistent |
Method 1 : Migrating data using Manual method
The first method of migrating data is a manual method. In this case as first step the output of MySQL table can be taken as a CSV file. There are various commands which can be used to do the same. Then this has to be uploaded into Redshift.
The disadvantages with this method is it is complex to achieve as there is no GUI. Apart from data migration, in case if you would like to do certain other things like some transformations, cleaning, calculations etc those are difficult to achieve.
Further, if such method fails then there is no automatic alerts or notifications, no rollbacks or other methods. Further in many cases we may want to do an initial load as a one time activity and on an ongoing basis load incremental load (change data capture), that is also difficult to achieve.
Also, in case if your database has many tables, this activity has to be done that many times and it’s very time consuming.
That is where Date Engineering / ETL tools are helpful.
Traditional Data Engineering tools and challenges
Though there are plenty of data engineering tools (free and paid, open source and proprietary) which can be used for planning and doing such kind of data migration activity. However there are certain challenges in using such traditional data engineering tools
- Most of the data engineering tools were built before AI and LLM, thus not leveraging the exciting features and capabilities offered by them.
- Learning curve: No matter which data engineering tool which you use, you will have a learning curve which is quite steep.
- Generally, with data migration there are also certain cases in which certain kind of other activities are also required like data cleaning, data type conversions, certain calculations etc. That requires even more technical know how of how to do the same.
- Depending on a data engineer who can do such activity. There is also often need of writing SQL, Python, Spark code etc. Hence very heavy dependence on highly technical resources.
- Most of these proprietary Data Engineering ETL tools are very costly
- Time consuming: It is also time consuming to do this activity because of its steep learning curve, dependence on tech developers.
Usage of AskOnData : A chat based AI powered Data Engineering Tool
Ask On Data is world’s first chat based AI powered data engineering tool. It is present as a free open source version as well as paid version. In free open source version, you can download and deploy on your own servers, whereas with enterprise version, you can use Ask On Data as a managed service.
Advantages of using Ask On Data
- Built using advanced AI and LLM, hence there is no learning curve.
- Simply type and you can do the required transformations like cleaning, wrangling, transformations and loading
- No dependence on technical resources
- Super fast to implement (at the speed of typing)
- No technical knowledge required to use
Below are the steps to do the data migration activity
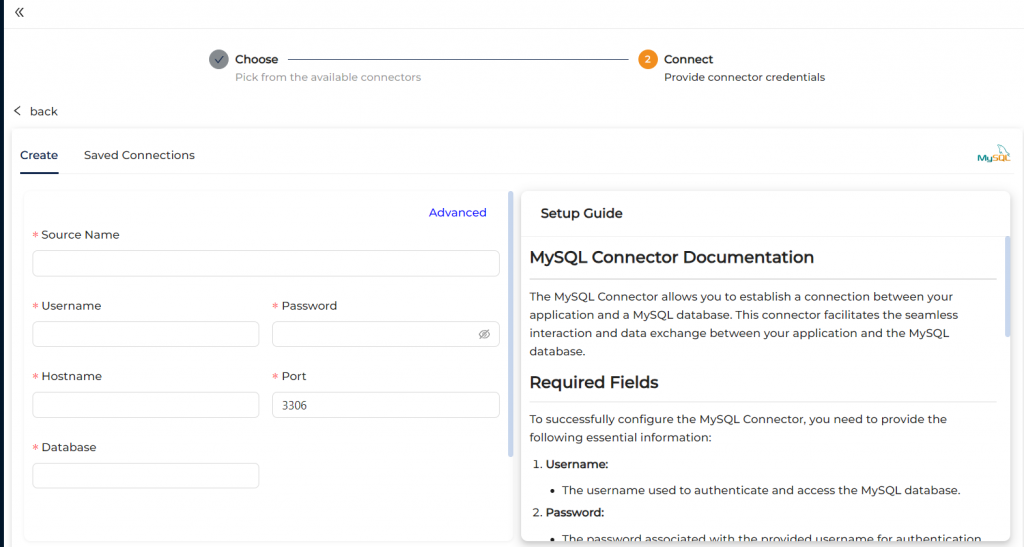
Step 1: Connect to MySQL (which acts as source)
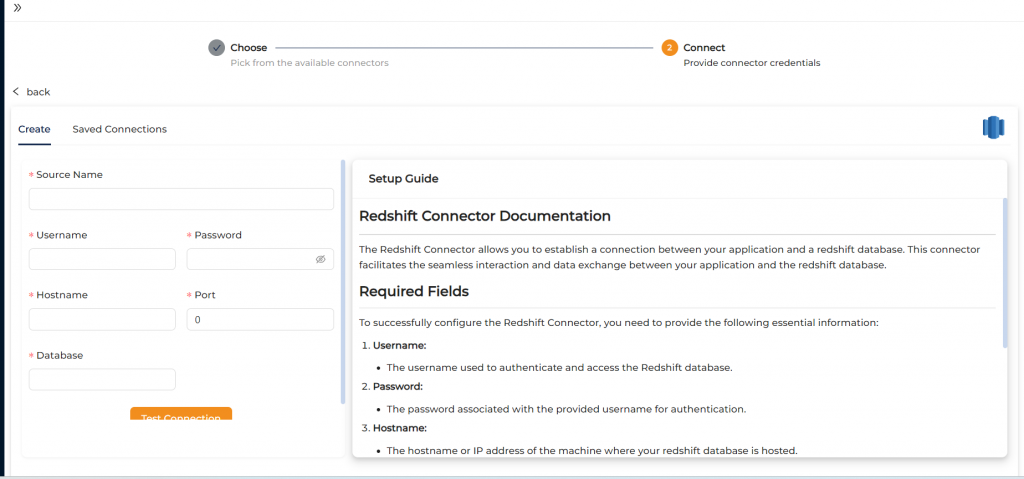
Step 2 : Connect to Redshift (which acts as target)
Step 3: Create a new job. Select your source (MySQL) and select which all tables you would like to migrate.
Step 4 (OPTIONAL): If you would like to do any other tasks like data type conversion, data cleaning, transformations, calculations those also you can instruct to do in natural English. NO knowledge of SQL or python or spark etc required.
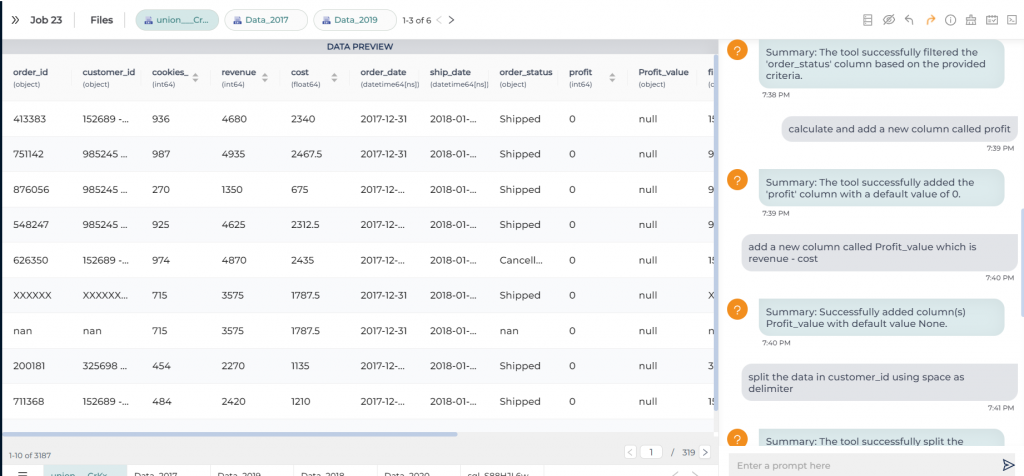
Step 5: Orchenstrate/schedule this. While scheduling you can run it as one time load, or change data capture or truncate and load etc.
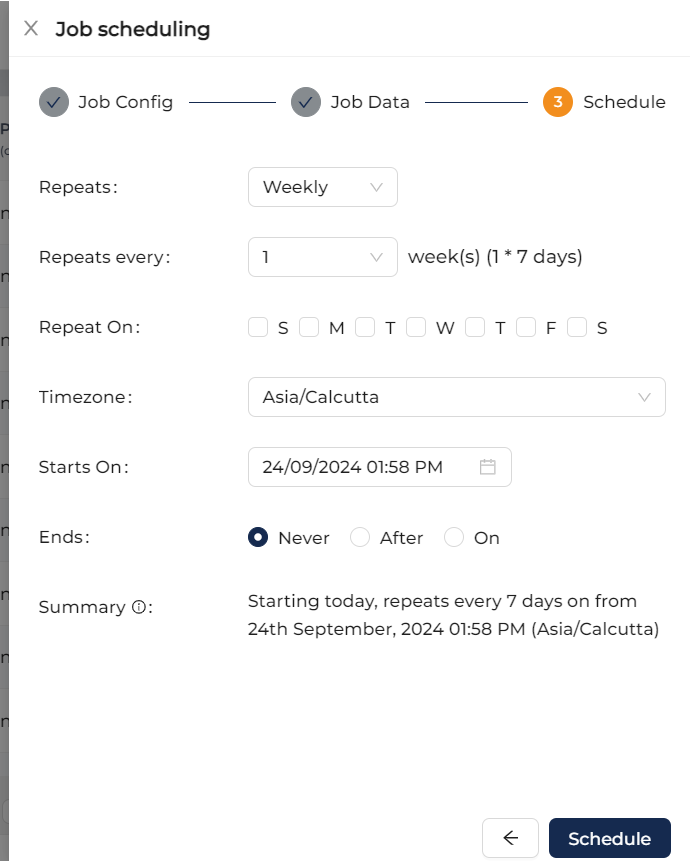
For more advanced users, Ask On Data is also providing options to write SQL, edit YAML, write PySpark code etc.
There are other functionalities like error logging, notifications, monitoring, logs etc which can provide more information like the amount of data transferred, logs, any error information if the job did not run and other kind of monitoring information etc.
Trying Ask On Data
You can reach out to us on support@askondata.com for a demo, POC, discussion and further pricing information. You can make use of our managed services or you can also download and install on your own servers our community edition from Github.
FAQs for Simplifying MySQL to Redshift Migration
Migrating to Redshift offers better scalability, improved query performance, and advanced analytics capabilities, making it ideal for handling large data volumes.
MySQL is suited for transactional data, while Redshift is optimized for complex data analytics, providing superior performance for big data workloads.
Ask On Data is a chat-based AI-powered tool that allows users to migrate data without technical knowledge, using simple natural language commands.
Manual migration lacks automation, requires repetitive tasks for multiple tables, and does not provide alerts or error handling, making it time-consuming.
Ask On Data offers quick implementation without the need for coding, eliminating the steep learning curve associated with traditional ETL tools. Schedule a demo to explore how Ask on Data can be the perfect fit for your data needs!